UTF-16인코딩 방법은 어떻게 될지 궁금해서 조사하였다.
UTF-8과는 다르게 UTF-16에서는 Surrogate pair 라는 용어가 등장하는데 UTF-16인코딩을 위해서 지정된 유니코드 영역을 표현하는 말이다. 그리고 Surrogate pair는 두가지 영역으로 나뉘게 된다.
High Surrogate, Low Surrogate 두가지로 나뉘어져 있다.
UTF-16이 기본적으로 2바이트를 사용하기에 인코딩할 문자 번호가 2바이트보다 작다면 Low(2바이트)만 이용이 되겠지만 U+10437과 같은 2바이트에 모두 담지 못하는 문자가 나타난다면 High와 Low가 조합이 되어 인코딩 된다.
예를들어 D801 DC37 (UTF-16) 이 있다면 D801은 High Surrogate, DC37은 Low Surrogate 로 구성되어있다는 것이다.
그럼 UTF-16인코딩 방법은 어떻게 될까?
유니코드 사이트의 식을 참고 하였다.
FAQ - UTF-8, UTF-16, UTF-32 & BOM
UTF-8, UTF-16, UTF-32 & BOM General questions, relating to UTF or Encoding Form Q: Is Unicode a 16-bit encoding? A: No. The first version of Unicode was a 16-bit encoding, from 1991 to 1995, but starting with Unicode 2.0 (July, 1996), it has not been a 16-
unicode.org

다음은 unicode.org에서 가져온 UTF-16의 기본식이다. 하지만 너무 복잡하기 때문에 보통 간편식을 사용한다고 한다.
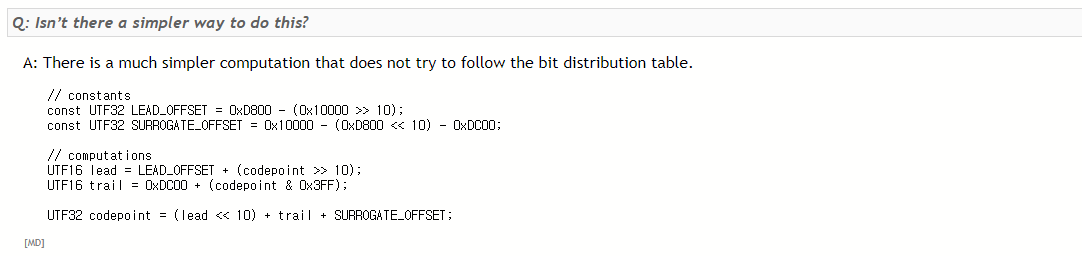
바로 위의 식이 UTF-16의 간편식이라고 할 수 있다.
그렇다면 이제 예를 들어 UTF-16을 인코딩 해보도록 하겠다.
(𐐷) = U+10437 을 예로 들어보겠다
앞에서 언급한것처럼 High와 Low를 나누어 계산해 주어야 하는데
1. High Surrogate
위의 계산식을 따라 가면 계산식의 lead에 해당하는 부분이다.
LEAD_OFFSET = 0xD800 - (0x10000 >> 10) = 0xD7C0
lead = 0xD7C0 + ( ( 0x10437 % 0x400 ( >>10 ) ) = 0x41 ) = 0xD801 이 나오게 된다.
2. Low Surrogate
계산식의 tail에 해당하는 부분이다.
trail = 0xDC00 + ( (0x10437 & 0x3FF) (= 0x400으로 나누어 남은 나머지) ) = 0xDC37이 된다.
마지막으로 High와 Low를 합쳐주게 되면
D801 DC37으로 표기가 된다.
UTF-8보다 인코딩방법이 쉽지는 않았지만 UTF-16 및 32도 특정 부분에서는 쓰이기 때문에 알아두면 쓸모가 있지 않을까 싶다.








최근댓글